目录
论文题目:VLA-AN: An Efficient and Onboard Vision-Language-Action Framework for Aerial Navigation in Complex Environments
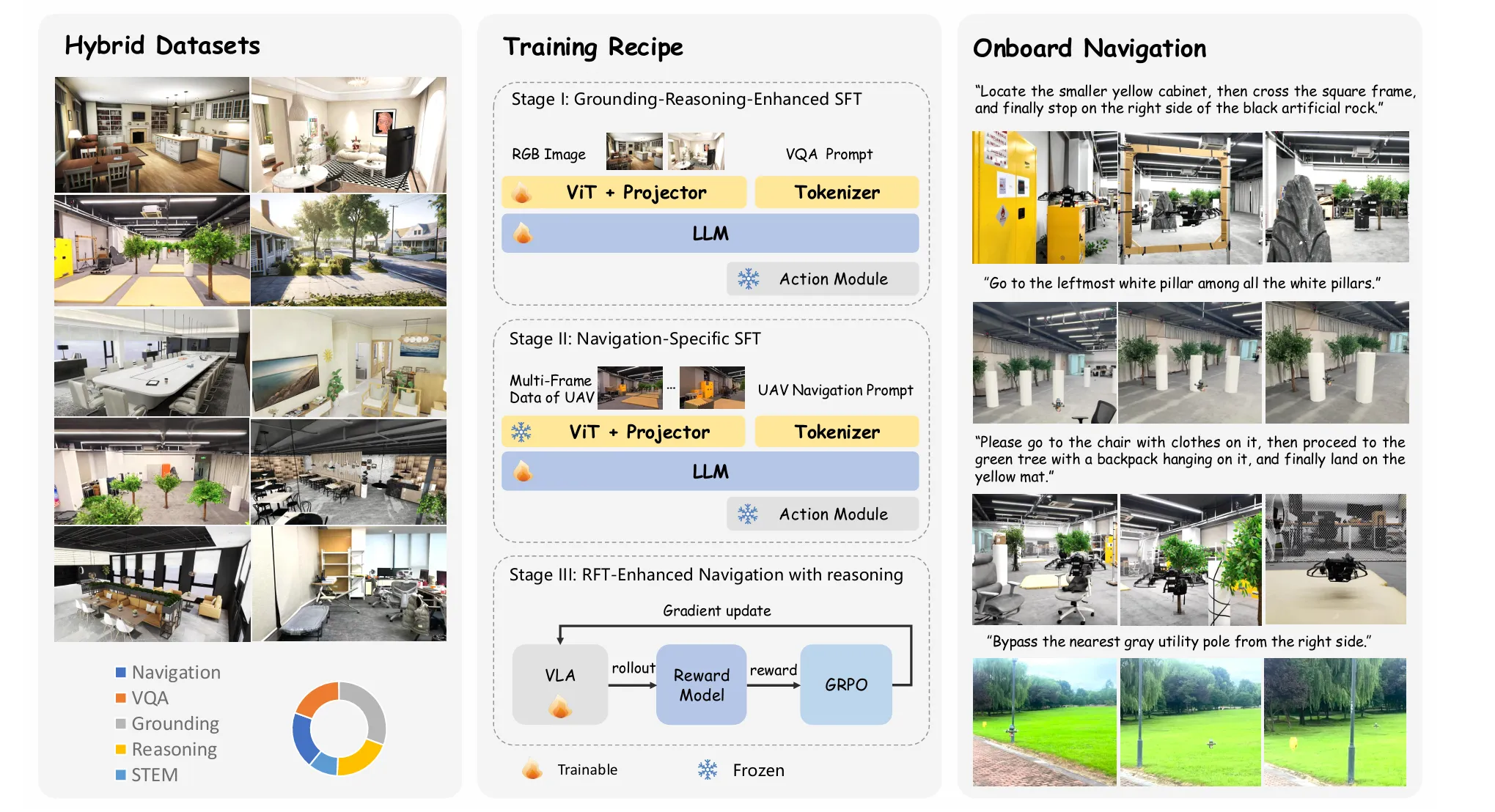
左侧(Hybrid Datasets):数据从哪里来?
为了解决“数据鸿沟”,VLA-AN 使用了一个混合数据集。
包含各种室内、室外场景的图片,也包含由导航指令、视觉问答、空间推理等任务构成的多模态数据(下方的饼图展示了数据组成)
一、为什么使用混合数据集?多模态数据的作用是什么?
如果只用无人机导航数据:模型可能会变成一个优秀的“飞行员”,但不是一个聪明的“任务理解者”。它可能飞得很稳,但无法理解“去第三个房间的白色椅子右边”这种需要空间推理和物体识别的复杂指令。
如果只用通用互联网图片数据:模型可能会认得猫猫狗狗、桌椅板凳,但它完全不知道从无人机的第一人称视角看世界是什么样子,也不知道该如何运动控制。
二、数据组成
1.通用视觉-语言数据:
内容:来自互联网的大规模图像-文本对、视觉问答(VQA)、空间关系描述(如“苹果在盘子里”)等。
作用:建立模型的 “世界观”和“常识” 。让模型学会:
- 识别万物:什么是椅子?什么是门?什么是“衣服”?
- 理解关系:“右边”、“后面”、“最近”这些空间概念是什么意思?
- 逻辑推理:根据指令“找到放着衣服的椅子”,它需要先识别“椅子”,再判断椅子上是否有“衣服”。
2.无人机专属导航数据:
- 内容:在仿真环境(如用3D-GS构建的高保真场景*)中,由无人机视角采集的RGB图像、深度图像,以及与之配对的动作序列(如3D航点、偏航角)。
- 作用:教会模型 “无人机视角”和“飞行技能”。让模型学会:
- 适应独特视角:理解从空中斜向下看的物体是什么样子的,应对运动模糊等动态场景。
- 学习运动控制:将语言指令和视觉感知映射到具体的飞行动作上(输出航点,而不是文本)
多模态数据的作用就是将不同形态的信息“对齐”到同一个语义空间中。
对于模型而言,RGB图像提供颜色纹理,深度图提供几何距离,语言指令提供任务目标,将这些信息融合,模型才能对环境和任务有更全面、更深刻的理解,从而做出精准的决策。
中间(Training Recipe):模型如何分阶段学习
Stage I(基础增强):用通用数据(VQA,空间定位)训练模型理解图片、理解空间关系。此时模型还不具备飞行能力,只是“看图说话”-(监督微调 SFT)
目标:将一个通用的语言模型,变成一个具备基本视觉理解能力的视觉-语言模型(VLM)
训练数据:主要使用上述的通用视觉-语言数据
学习过程:
- 输入一张图片和一段相关问题(如:“图片里有什么?椅子在桌子的哪边?”)。
- 模型尝试生成答案(如:“有一张桌子和一把椅子。”、“椅子在桌子的左边。”)。
- 训练目标是最小化模型生成的答案和标准答案之间的差异。
达成效果:模型不再是“文盲”,它变成了一个能看懂图片、理解空间关系的“视觉专家”。此时,如果你问它问题,它能用文字回答你,但它还不知道如何控制无人机飞行。
Stage II(导航专项):导航专项训练(监督微调 SFT):注入真实的无人机导航数据,模型开始学习输出3D航点和偏航角,具备了控制无人机飞行的基本技能。
目标:让上阶段培养的“视觉专家”学习无人机导航的专项技能
训练数据:主要使用无人机专属导航数据,并混合一部分通用数据以防遗忘基础能力
学习过程:
关键转变:
- 输入是无人机的实时视角图片和语言指令(如:“飞向门口”)。
- 模型的输出改变——不再是回答问题的文本,而是直接输出控制指令:下一个目标的3D坐标(Waypoint)和机头朝向(Yaw)。
- 训练目标是让模型输出的航点尽可能接近数据集中专家规划的理想航点。
达成效果:模型能将语言指令和视觉场景转化为具体的飞行动作,现在能执行基本的导航任务。但面对非常复杂、需要长远规划的任务时,可能还会出错
Stage III(推理增强):
目标:超越模仿,培养模型在复杂、未知环境中的主动决策和推理能力。
训练方法:强化学习(RL),特别是GRPO策略(deepseek-R1模型中使用到的强化学习算法)
学习过程:
- 实践:模型在仿真环境中执行一个长序列任务(如:“绕过桌子,飞到最里面的窗户旁边”)。
- 评估:一个“裁判系统”(奖励函数)会根据多项指标给模型的表现打分(Reward)。打分标准包括:
- 任务成功与否:最终是否到达了正确位置?
- 动作质量:飞行轨迹是否平滑、高效?
- 安全系数:是否远离障碍物?
- 推理正确性:中间的理解和决策步骤是否合理?
- 进化:模型会尝试多种不同的策略来完成同一个任务。通过比较不同策略得到的奖励分数(图中的 Gradient Update),模型会自动倾向于学习能获得更高奖励的行为,并摒弃低效或危险的行为。、
达成效果:模型不再是机械地模仿数据,而是学会了“思考”。它能够为了长远的目标(如完成多步指令)而做出临时的局部决策(如先绕行),表现出强大的长时序任务能力和在陌生环境中的鲁棒性。
右侧(Onboard Navigation):最终要做什么
展示了模型训练的最终目标:在真实无人机上,根据自然语言指令(如“飞到放着衣服的椅子右边”),完成在复杂场景中的飞行导航。
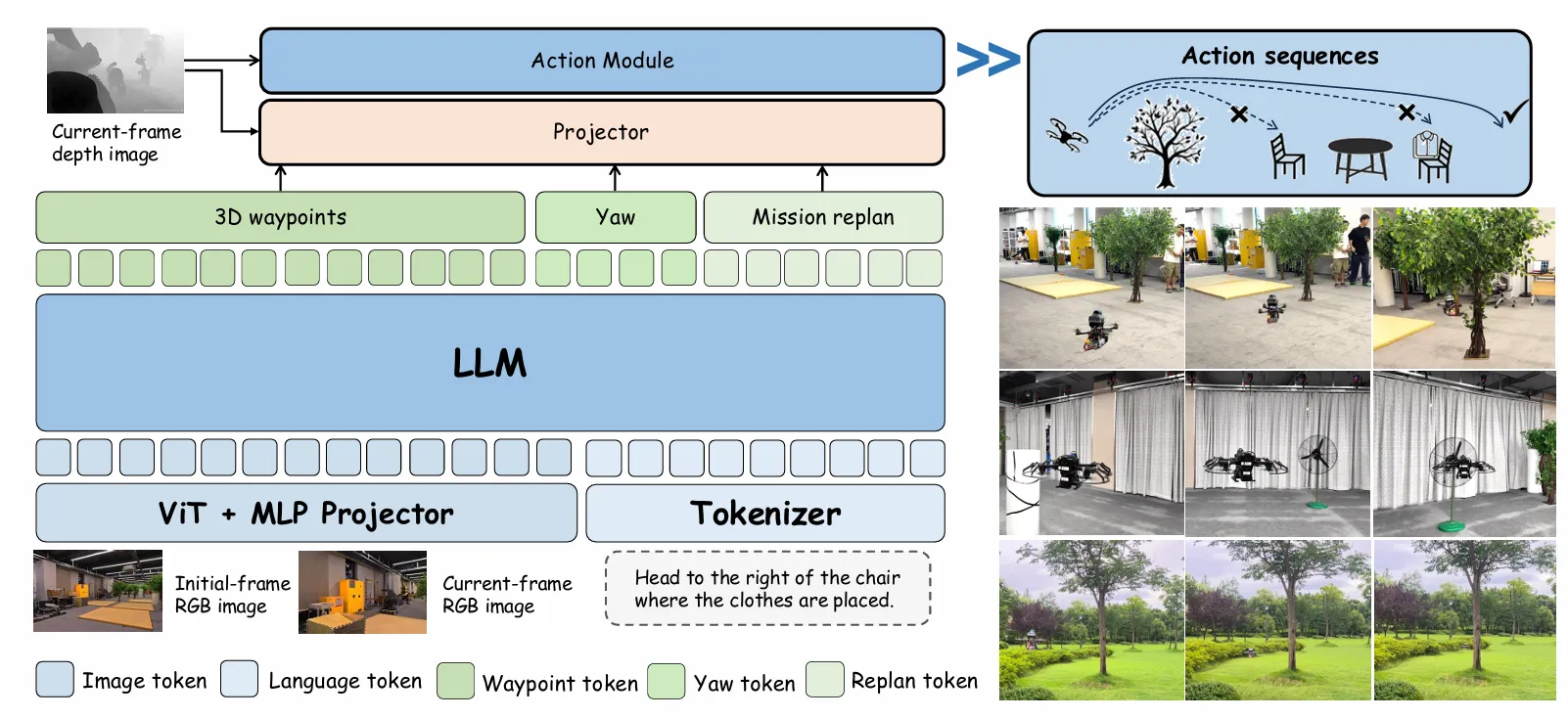
Tokenizer(分词器):
这是LLM的“语言处理器”。它的任务是将人类输入的自然语言指令(如“飞到椅子右边”),拆分成模型能够处理的最小单元——Token(令牌/词元)。例如,“飞”、“到”、“椅子”、“右边”可能各自成为一个Token,同时还会添加一些特殊Token来表示句子的开始和结束。
经过Tokenizer处理,一段话就变成了一串数字ID,这串ID就是Language Token(语言令牌),可以输入给LLM理解。
实验验证:仿真与真机性能
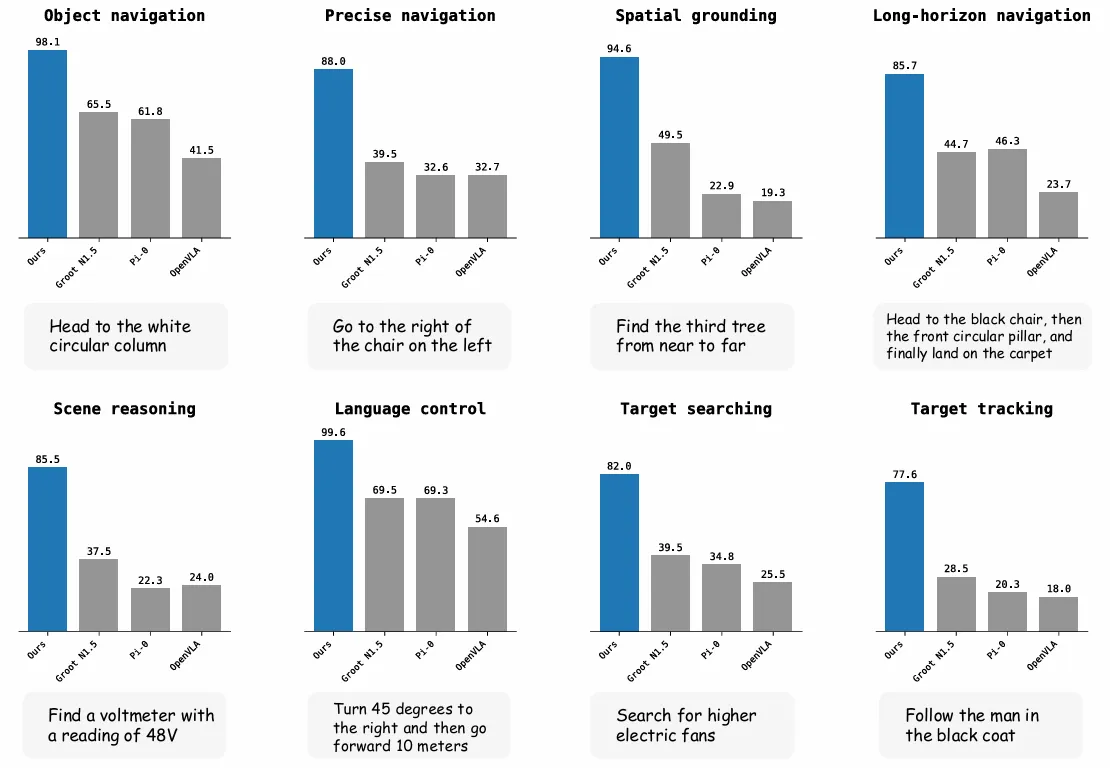
- 基准测试对比 任务类型:物体导航、空间定位、长序列导航等8类场景。 结果: VLA-AN在物体导航任务中成功率最高达 98.1%,显著优于OpenVLA、π₀等基线模型。 长序列任务中,得益于RFT阶段,成功率提升至 85.7%,而基线模型因灾难性遗忘表现较差。 数据泛化性: 仅使用3D-GS数据的模型性能接近真实数据训练结果,而网格数据模型在未见场景中成功率下降约20%。
 2. 真机部署表现
平台:搭载Intel RealSense相机与Jetson Orin NX的微型无人机。
能力:
理解复杂指令(如“左转90度后向右飞向黄色柜子,找到钟表图标”),完成多步任务分解与执行。
在目标移动等动态场景中,通过重规划机制维持 90%+ 成功率。
推理效率:
7B模型解码速度 0.110 s/token,2B模型仅 0.032 s/token,满足实时需求。
2. 真机部署表现
平台:搭载Intel RealSense相机与Jetson Orin NX的微型无人机。
能力:
理解复杂指令(如“左转90度后向右飞向黄色柜子,找到钟表图标”),完成多步任务分解与执行。
在目标移动等动态场景中,通过重规划机制维持 90%+ 成功率。
推理效率:
7B模型解码速度 0.110 s/token,2B模型仅 0.032 s/token,满足实时需求。
*高保真混合数据集构建:
- 利用 3D Gaussian Splatting (3D-GS) 技术重建真实场景,替代传统网格渲染。
采集真实场景视频,转换为高保真3D-GS模型并导入Unity引擎: Unity 是一款非常强大且流行的游戏引擎,能够高质量地渲染像3D-GS这样的复杂模型,创造出极其逼真的视觉环境。
为无人机AI创造了一个既安全(在电脑里训练,撞了也没损失)、又极其逼真(因为场景和现实几乎一样)的训练环境。
无人机AI在模拟器里学到的“飞行技巧”(比如如何识别一把真实的椅子、如何绕过一扇真实的门),就能更好地直接应用到真实世界中,从而极大地弥合了“虚拟”和“现实”之间的鸿沟。
本文作者:cc
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!