基础公式推导
例子:尺寸测量
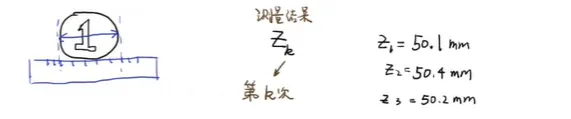
测量几次,使用取平均值方法去估计真实数据,其中x^k为测量k次的估计值,x^k−1为测量k-1次的估计值
x^k=k1(z1+z2+⋯+zk)=k1(z1+z2+⋯+zk−1)+k1zk=k1k−1k−1(z1+z2+⋯+zk−1)+k1zk=kk−1x^k−1+k1zk=x^k−1−k1x^k−1+k1zk
即
x^k=x^k−1+k1(zk−x^k−1)
- k↑,k1→0.x^k→x^k−1
随着k增加,测量结果不再重要
直观理解是有了大量的数据后,对估计结果比较有信心,因此以后的测量值相对而言也就没那么重要了
- k 小,k1 大,测量值zk 作用较大
测量值和估计值差距较大时,zk作用会被放大
令k1=Kk,则有
x^k=x^k−1+Kk(zk−x^k−1)
当前的估计值 = 上一次的估计值 + 系数 × (当前测量值 − 上一次的估计值)
其中Kk为卡尔曼增益
公式体现了一种递归的思想,也体现了卡尔曼滤波的优势——不需要追踪很久以前的数据,只需要上一次的就可以了
引入估计误差eEST和测量误差eMEA,那么卡尔曼增益可以表示为
Kk=eESTk−1+eMGAkeESTk−1
在k时刻,若k-1时刻的估计误差远大于k时刻的测量误差,对于x^k的取值,认为更加可以信任测量值
eESTk−1≫eMEAk:kk→1x^k=x^k−1+zk−x^k−1=zk
相反,若测量误差很大时,选择相信上一次的估计值
eESTk−1≪eMEAkKk→0x^k=x^k−1
例子:使用卡尔曼滤波估计某物体真实长度
在存在测量噪声的情况下,卡尔曼滤波如何最优地估计真实值
 问题设定
问题设定
- 真实状态:物体的真实长度 x = 50 mm(一个固定但未知的值,我们试图去估计它)。
- 初始猜测:我们从一次不准确的推测开始,x̂₀ = 40 mm,并且对这个猜测非常不确定,初始估计误差 e_EST₀ = 5 mm。
- 测量工具:我们有一个测量仪器,每次测量会带来噪声。从表格看,测量值 Z_k围绕50上下波动 (如51, 48, 47...),且仪器的测量噪声 e_MEA = 3 mm(恒定)
核心矛盾:我们既有“不准确但动态更新的预测(估计)”,又有“有噪声但反映部分真实情况的观测(测量)”。应该相信哪一个?相信多少?卡尔曼滤波给出了最优的融合方案
卡尔曼滤波的解决方法:三步循环
第一步:计算卡尔曼增益 K_k
Kk=eESTk−1+eMEAeESTk−1
卡尔曼增益是一个 “信任权重”,范围在0到1之间。
它如何解决问题?
- 分子e_EST:代表我们当前估计的不确定性。这个值越大,说明我们对自己的上一次估计越没信心。
- 分母加入了 e_MEA:代表测量的不确定性。
- 逻辑:如果我们自己的估计很不确定(e_EST很大),而测量相对可靠(e_MEA较小),那么 K_k就接近1,意味着我们会更相信新的测量值。反之,如果我们自己的估计已经很确定(e_EST很小),而测量噪声很大,那么 K_k就接近0,意味着我们会更倾向于维持原来的估计。
- 在例子中:
- k=1时:K₁ = 5 / (5+3) = 0.625。初始估计误差(5)比测量误差(3)大,所以我们更信任测量,增益值较高。
- k=2时:K₂ = 1.875 / (1.875+3) ≈ 0.385。经过第一次融合,估计误差变小了(1.875),我们对估计的信心增加了,因此对新测量的信任权重就降低了。
第二步:更新状态估计——信息融合的核心步骤
x^k=x^k−1+Kk(Zk−x^k−1)
它如何解决问题?
- (Z_k - \hat{x}_{k-1})是 “测量残差”或“新息”,即测量值与我们上一轮估计的差异。
- 我们不是简单地用测量值替换旧估计,也不是无视测量值,而是用卡尔曼增益 K_k作为比例,将这个差异的一部分“吸收”到我们的新估计中。
- 结果:新估计 x̂_k是旧估计和测量值的一个加权平均。K_k决定了向测量值“滑动”多少。
- 在例子中:
- k=1:x̂₁ = 40 + 0.625 * (51 - 40) = 46.875。初始估计40和首次测量51的差异是11,我们取了这个差异的62.5%,将估计值从40大幅更新到46.875。
- k=2:x̂₂ = 46.875 + 0.385 * (48 - 46.875) ≈ 47.308。差异很小(1.125),且我们只信任了38.5%,所以更新幅度很小。估计值开始收敛。
第三步:更新估计误差——代表了对当前新估计的信心度的更新
eESTk=(1−Kk)eESTk−1
它如何解决问题?
- 经过一次融合,我们结合了新的信息,理论上应该对我们得出的新估计更有把握了。
- 公式 (1 - K_k)必然小于1,所以 e_EST会随着迭代不断减小。这反映了卡尔曼滤波的“学习”过程:随着数据积累,估计的不确定性降低,估计值趋于稳定。
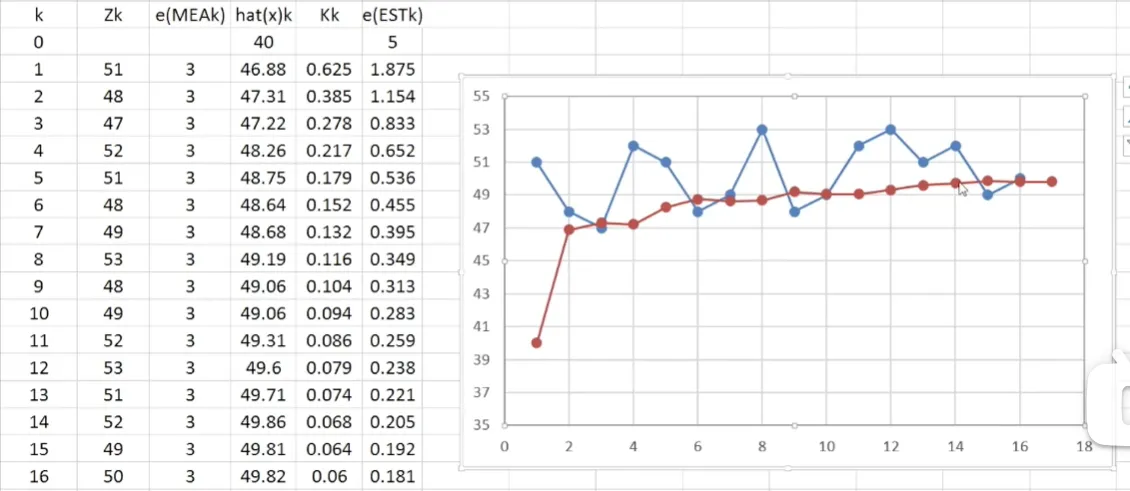
- 在例子和Excel表格中:
- k=1:e_EST₁ = (1-0.625) * 5 = 1.875
- k=2:e_EST₂ ≈ (1-0.385) * 1.875 ≈ 1.154
- 从Excel表可以看到,e_EST从5逐渐减小到0.181 (k=16),估计的置信度越来越高
总结
卡尔曼滤波作用
- 量化不确定性:始终用数值 (e_EST, e_MEA) 跟踪“预测”和“观测”的可信度。
- 动态计算权重:通过卡尔曼增益 K,根据双方的可信度实时决定该相信谁多一些。
- 最优融合:以加权平均的方式,将预测和观测结合起来,得到比单一信息源都更优的新估计。
- 持续进化:每得到一次新数据,就重复一次“预测→测量→加权融合→更新信心”的循环,使估计值不断逼近真实状态,同时信心不断增强。
因此,卡尔曼滤波解决的就是如何在噪声中通过连续、不确定的观测,智能地估计出一个动态(或静态)系统的最优状态的问题。
系统方程
离散系统的状态空间方程:
Xk=AXk−1+BUkZk=HXk
往模型中加入不确定性:
- 模型不准确,加入过程噪声ωk−1
Xk=AXk−1+BUk+ωk−1
- 传感器不精确,加入测量噪声vk,表示测量过程中产生的不确定性
Zk=HXk+vk
问题出现:在模型不够准确,测量也不够精确的情况下,如何去估计x^k
Q=E[ωωT]的推导过程
过程噪声ωk满足正态分布P(ω)∼(0,Q)
定义"随机噪声"就是均值为0的随机过程,均值不为0的部分称为"偏置"或"系统误差",不叫"噪声"
- 噪声向量 ω=[w1w2]
- 转置 ωT=[w1w2]
ωωT=[w1w2][w1w2]=[w1×w2w2×w1w1×w2w2×w2]=[w12w2w1w1w2w22]
E[ωωT]=E[[w12w2w1w1w2w22]]=[E[w12]E[w2w1]E[w1w2]E[w22]]
因为噪声均值为0,E(w1)=0,根据方差公式(方差=平方的均值-均值的平方):
VAR(w1)=E(w12)−[E(w1)]2=E(w12)−0=E(w12)
另一个角度(μ1为0):
Var(w1)=E[(w1−μ1)2]
协方差公式:
Cov(w1,w2)=E[(w1−μ1)(w2−μ2)]=E[w1w2]
噪声均值为0,即μ1和μ2 为0
Cov(w1,w2)=E[(w1−0)(w2−0)]=E[w1w2]
综合
E[wp2]=Var(wp)E[wv2]=Var(wv)E[wpwv]=Cov(wp,wv)
因此,有
Q=E[ωωT]=[Var(wp)Cov(wv,wp)Cov(wp,wv)Var(wv)]
同理,测量噪声vk满足分布P(v)∼(0,R),R为协方差矩阵
如何融合
现实中,对于过程噪声ωk−1和测量噪声vk无法建模,我们掌握的只有
x^k−=Ax^k−1+Buk−1zk=Hxk
其中,x^k−是先验估计,即通过状态空间方程去掉过程噪音,计算得到的结果
根据测量结果zk,可以得到
x^kmea =H−zk
此时,我们有了算出来的结果x^k−和测出来的结果x^kmea ,但噪声依旧是不能被完整建模的
如何通过两个不太准确的结果得到一个准确的结果呢?
使用数据融合:将计算结果和测量结果融合在一起
x^k=x^k−+G(H−zk−x^k−)
其中,x^k代表后验值
令G=kkH
x^k=x^kˉ+kk(zk−Hx^kˉ)
kk∈[0,H−],kk=0时,x^k−=x^k,选择相信计算结果;Kk=H−时,x^k=H−zk,选择相信计算结果
接下来的目标:寻找Kk,使得误差最小,即 x^k→实际值xk
Kk与误差有关,比如测量误差大,那么肯定会更愿意相信计算值
引入误差:
ek=xk−x~k
ek同样满足正态分布 p(lk)∼(0,P),P为协方差矩阵
P=E[ee⊤]=[σe12σe2σe1σe1σe2σe22]
若估计结果距离实际值越小,则误差的方差也是最小的
那么可以通过一下思路实现这个目标:寻找Kk使得P矩阵的迹tr(P)最小
tr(p)=σe12+σe22
卡尔曼增益推导过程
下面是实现这一目标的推导过程:
P=E[ee⊤]=E[xk−x^k)(xk−x^k)⊤]
将x^k=x^kˉ+kk(zk−Hx^kˉ)带入
xk−x^k=xk−(x^kˉ−+kk(zk−Hx^k−))=xk−x^k−−kk(zk)+kkHx^kˉ−=xk−x^k−−kk(Hxk+vk)+kkHx^kˉ−=xk−x^k−−kkHxk−kkvk+kkHx^k−=(xk−x^kˉ)−kkH(xk−x^kˉ)−kkvk=(I−kkH)(xk−x^k−)−kkvk
定义先验误差ek−=xk−x^k−,则
P=E[ee⊤]=E[xk−x^k)(xk−x^k)⊤]=E[((I−kkH)ek−−kkvk][(I−kkH)ek−−kkVk)]⊤]
由(AB)⊤=B⊤A⊤(A+B)⊤=A⊤+B⊤,所以先写出第二项的转置:
[(I−kkH)ek−−kkvk)]⊤=ek−⊤(I−kkH)⊤−vk⊤kk⊤
展开括号内的乘积,原式等于
P=E[(I−kkH)ek−ek−⊤(I−kkH)⊤−(I−kkH)ek−vk⊤kk⊤−kkvkek−⊤(I−kkH)⊤+kkvkvk⊤kk⊤]
对其中的每一项单独求期望:
提出常数
E[(I−kkH)ek−vk⊤kk⊤]=(I−kkH)E[ek−vk⊤]kk⊤=0
若A、B相互独立,则有E(AB)=E(A)E(B),由于ek−与v_k不相关且各自的均值为零,因此交叉项期望为零
同理:
E[kkvkek−⊤(I−kkH)⊤]=0
于是
P=(I−kkH)E[ek−ek−⊤](I−kkH)⊤+kkE[vkvk⊤]kk⊤
由协方差矩阵形式P(v)∼(0,R),E[vv⊤]=R,记Pk−=E[ek−ek−⊤],Rk=E[vkvk⊤]
Pk=(I−kkH)Pk−(I−kkH)⊤+kkRkkk⊤=(Pk−−kkHPk−)(I⊤−H⊤kk⊤)+kkRkk⊤=Pk−−kkHPk−−Pk−H⊤kk⊤+kkHPk−H⊤kk⊤+kkRkk⊤
这就是误差的协方差矩阵合并后的表达式,通常用于卡尔曼滤波中推导最优增益kk时对Pk的展开
还记得目标是什么吗?目标是估计和实际的误差最小,通过P矩阵的迹反映
tr(Pk)=tr(Pk−)−2tr(kkHPk−)+tr(kkHPk−H⊤kk⊤)+tr(kkRkk⊤)
通过dkkdtr(pk)=0来寻找使迹最小的kk
结合一些计算公式,最终可以得到
Kk=HPk−H⊤+RPk−H⊤
当测量噪声协方差矩阵R很大时,kk→0
x^k=x^k−
取先验估计作为估计值
卡尔曼滤波数据融合流程
对于系统:
Xk=AXk−1+BUk−1+Wk−1Zk=HXk+vkω∼p(0,Q)v∼p(0,R)
我们有:
先验估计:
x^k−=Ax^k−1+Buk−1
后验估计,使用了数据融合,选取不同的kk,就会不同程度倾向于观测或者计算结果:
x^k=x^k−+kk(zk−Hx^k−)
卡尔曼增益:
kR=HPk−H⊤+RPk−H⊤
对于以上的公式,我们缺少的是Pk−的信息,因此需要求出Pk−
Pk−=E[ek−ek−T]
先验误差为真实值减去先验估计值
ek−=xk−x^k−=Axk−1+Buk−1+ωk−1−Ax^k−1−Buk−1=A(xk−1−x^k−1)+wk−1=Aek−1+ωk−1
Pk−=E[ek−ek−T]=E[(Aek−1+ωk−1)(Aek−1+ωk−1)⊤]=E[(Aek−1+ωk−1)(ek−1⊤A⊤+ωk−1⊤)]=E[Aek−1ek−1⊤A⊤+Aek−1ωk−1⊤+ωk−1ek−1⊤A⊤+ωk−1ωk−1⊤]
对其中的项分别求期望,E(ek−1wk−1)=E(ek−1)E(wk−1),E(ek−1)=0,E(wk−1)=0
所以原式
=AE[ek−1ek−1⊤]A⊤+E[wk−1wk−1⊤]=APk−1A⊤+Q
现在我们就有了先验误差的协方差矩阵表示了,可以利用卡尔曼滤波器估计状态变量的值了
分为两个步骤:预测和校正

有了这五步,就可以得到卡尔曼滤波的最优估计值了
扩展卡尔曼滤波
系统表达
xk=f(xk−1,μk−1,wk−1)zk=h(xk,vk)
其中,f 和 h为非线性函数;w 和 v 为过程噪声与观测噪声
状态方程的泰勒展开
问题:当一个正态分布(高斯分布)的随机变量通过非线性系统(f或 h)后,其分布将不再保持正态性。这使得基于高斯假设的经典卡尔曼滤波器无法直接应用
解决方案:为了处理非线性,引入线性化技术,核心工具是泰勒展开
选取展开点:
- 对于状态方程:在滤波过程中,系统的真实状态xk是未知的(存在误差),因此无法在真实点进行线性化,因此选择在上一次的最优估计点x^k−1(即后验估计)作为泰勒展开的参考点
- 通常将过程噪声wk−1在其均值点(0点)附近进行线性化
- uk−1是已知的确定性输入,而非待估计的随机变量,因此uk−1是作为展开点的一个已知坐标代入的
xk=f(xk−1,uk−1,wk−1)≈f(x^k−1,uk−1,0)+∂x∂f(x^k−1,0)⋅(xk−1−x^k−1)+∂w∂f(x^k−1,0)⋅(wk−1−0)
将非线性函数 f 在点 (x^k−1, 0)处,围绕其两个变量xk−1和wk−1展开,偏导都是对第一个和第三个自变量求的,因为第二个自变量控制输入 uk−1是已知的,不参与线性化
定义状态方程的雅可比矩阵
Ak−1=∂x∂f(x^k−1,uk−1,0)
- 过程噪声雅可比矩阵Wk−1:
Wk−1=∂w∂f(x^k−1,uk−1,0)
代入后,线性化方程变为:
xk≈f(x^k−1,uk−1,0)+Ak−1(xk−1−x^k−1)+Wk−1wk−1
观测方程的泰勒展开
选取展开点:
- 对于观测方程:在 k 时刻,我们尚未得到测量值 zk之前,我们拥有的是基于 k-1时刻信息的状态预测值xk−, xk−=f(x^k−1,uk−1,0)
- 计算 k 时刻状态的先验状态估计xk−
- 噪声在其均值点线性化:通常假设测量噪声 vk的均值为0,所以我们在线性化时,将vk设为其均值 0
因此,标准EKF的线性化点为:(xk−, 0)
zk=h(xk,vk)≈h(xk−,0)+∂x∂h(xk−,0)⋅(xk−xk−)+∂v∂h(xk−,0)⋅(vk−0)
定义观测方程的雅可比矩阵
Hk=∂x∂h(xk−,0)
Vk=∂v∂h(xk−,0)
代入后,方程变为:
zk≈h(xk−,0)+Hk(xk−xk−)+Vkvk
扩展卡尔曼滤波的标准更新方程
xk−=f(x^k−1,Uk−1,0)Pk−=APk−1AT+WQWTKk=(Pk−HT)/(HPk−HT+VRVT)x^k=xk−+Kk(zk−h(xk−,0))Pk=(I−KkH)Pk−