目录
LSTM
在无人船姿态预测中的应用:
- 输入:当前时刻的横摇角、纵摇角。
- 历史信息:之前时刻的姿态数据(保存在细胞状态和隐藏状态中)。
- 处理:LSTM 学习姿态变化的规律(时间序列)。
- 输出:预测未来时刻的姿态。
上一个隐藏状态代表过去信息,和当前输入的信息拼接起来,通过遗忘门,网络模型会决定遗忘门输出的值(0-1)为多少,从而决定记忆细胞保留多少过去的信息,0-1范围内,输出越大,保留信息越多——过去信息的取舍
上一个隐藏状态代表过去信息,和当前输入的信息拼接起来,通过输入门,网络模型会决定输入门输出的值(0-1)为多少,从而决定保留多少现在的新信息(即候选记忆细胞所代表的新信息),0-1范围内,输出越大,保留信息越多——新信息的取舍
两者求和,更新新的记忆细胞,这表示我们完成了对新旧信息分别取舍之后,所生成的新状态
上一个隐藏状态代表过去信息,和当前输入的信息拼接起来,通过输出门,网络模型会决定输出门输出的值(0-1)为多少,从而决定从更新后的细胞状态中输出多少信息到隐藏状态,输出越大,表示从细胞状态中输出的信息越多。即细胞状态中的信息对当前时刻很重要,这些信息应该被用于当前时刻的预测
框架图:
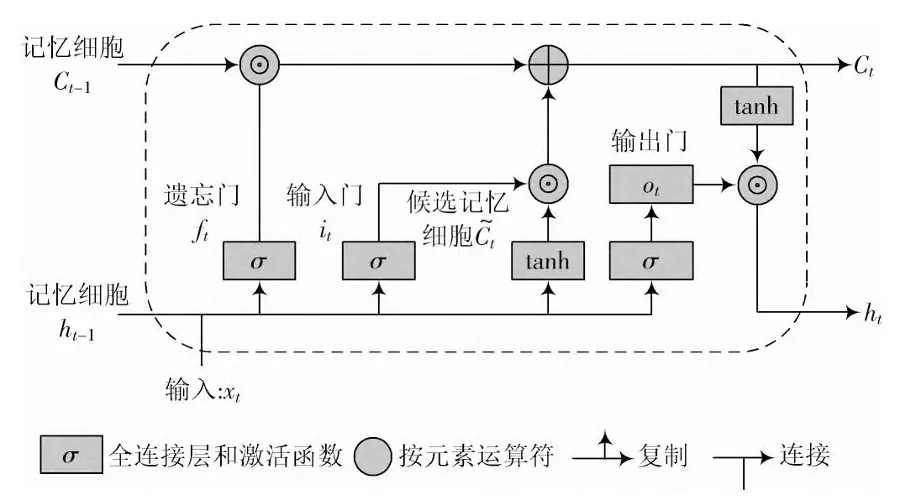
式中,——遗忘门的权重矩阵和偏置向量;——输入门的权重矩阵和偏置向量;——输出门的权重矩阵和偏置向量;——激活函数,通常为tanh函数、Sigmoid函数;—t时刻输入到LSTM中的数据、记忆状态和相对应的输出数据
在图片中的步骤显示
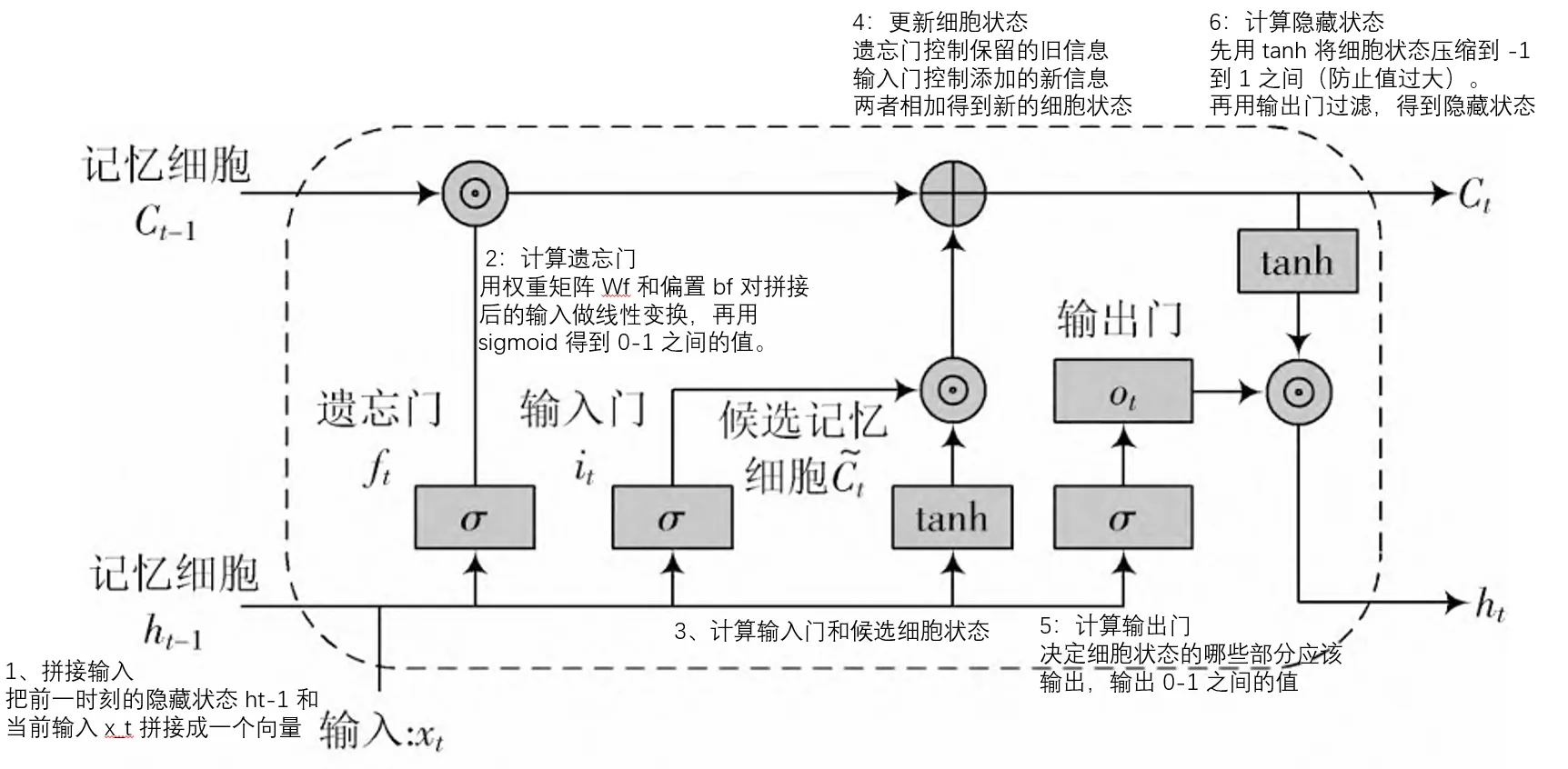
步骤 1:拼接输入- 为什么要把历史信息和当前输入拼接
公式:concat_input =
原理:
- 决策需要同时考虑历史(ht-1)和当前(Xt)
- 拼接后,权重矩阵可以同时学习两者的关系
含义:
- 把前一时刻的隐藏状态 ht-1 和当前输入 Xt 拼接成一个向量
- 例如:ht-1 是 [0.3, 0.6, 0.4],Xt 是 [0.8, 0.5],拼接后是 [0.3, 0.6, 0.4, 0.8, 0.5]
例子:
- 预测无人船姿态时,需要同时看:
- 历史:之前是上升趋势
- 当前:当前输入是下降
- 拼接后,模型能学习“历史上升 + 当前下降 = 可能转向”这类模式
设计思想:
- 让模型同时感知历史和当前,做出更准确的决策。
步骤 2:计算遗忘门- 需要决定保留多少旧信息
公式:ft = σ(Wf · concat_input + bf)
含义:
- 输入:前一时刻的隐藏状态
ht-1和当前输入Xt - 输出:一个 0 到 1 之间的值
- 接近 0:完全遗忘该信息
- 接近 1:完全保留该信息
遗忘门的作用:
- 决定从细胞状态中保留多少旧信息
- 值接近 1:保留;接近 0:遗忘
- 例如:ft = [0.69, 0.76, 0.68] 表示第 1 维保留约 69%,第 2 维约 76%,第 3 维约 68%
不是所有历史信息都永远有用。有些会过时,有些需要长期保留,遗忘门让模型自动决定保留比例
例子:
- 预测姿态时:
- 长期趋势(如周期性)应保留
- 短期噪声应遗忘
- 遗忘门自动学习哪些该保留、哪些该遗忘。
步骤 3:计算输入门和候选细胞状态
公式:
- it = σ(Wi · concat_input + bi)(输入门)
- Ct_tilde = tanh(Wc · concat_input + bc)(候选细胞状态)
- 候选细胞状态是“可能的新信息”,通过tanh函数生成,还不是最终进入细胞状态的内容。它需要经过输入门的筛选,才能决定是否以及以多少比例加入细胞状态
在细胞状态更新中的应用 例:
假设候选状态包含 3 个维度的信息:
- 候选状态:Ct_tilde = [0.8, -0.3, 0.5]
- 第 1 维:0.8(可能表示横摇角的变化)
- 第 2 维:-0.3(可能表示纵摇角的变化)
- 第 3 维:0.5(可能表示艏摇角的变化)
输入门决定每个维度的记录强度:
- 输入门:it = [0.9, 0.1, 0.7]
- 第 1 维:0.9(记录 90%,表示这个变化很重要)
- 第 2 维:0.1(记录 10%,表示这个变化可能是噪声,只记录 10%)
- 第 3 维:0.7(记录 70%)
- 如此,模型可以自动判断哪些信息重要、哪些不重要,对不同信息采用不同的记录强度
最终记录到细胞状态的值:
- 第 1 维:0.9 × 0.8 = 0.72
- 第 2 维:0.1 × (-0.3) = -0.03
- 第 3 维:0.7 × 0.5 = 0.35
输入门(it):
- 决定哪些新信息值得存储,输出 0-1 之间的值。
候选细胞状态(Ct_tilde):
- 包含可能的新信息,用 tanh 压缩到 -1 到 1 之间。
步骤 4:更新细胞状态
原理:
- 细胞状态是长期记忆载体,保存了预测所需的历史模式,更新方式要能保留长期信息,同时融入新信息
公式:Ct = ft * Ct-1 + it * Ct_tilde
含义:
- 旧信息部分:ft * Ct-1(遗忘门控制保留的旧信息)
- 新信息部分:it * Ct_tilde(输入门控制添加的新信息)
- 两者相加得到新的细胞状态。
步骤 5:计算输出门-选择对预测有用的信息
原理:
- 不是所有细胞状态内容都需要在当前时刻输出,输出门控制输出内容,让输出更聚焦。
不同任务需要的信息不同,输出门让模型根据任务选择输出。
公式:ot = σ(Wo · concat_input + bo)
含义:
- 决定细胞状态的哪些部分应该输出,输出 0-1 之间的值
例子:
- 细胞状态:ct = [0.8, 0.5, 0.3](包含多种信息)
- 输出门:ot = [0.9, 0.2, 0.7](只输出第 1、3 维)
- 结果:只输出相关部分,过滤不相关信息。
步骤 6:计算隐藏状态
公式:ht = ot * tanh(Ct)
- 输出门过滤后的细胞状态
隐藏状态的作用:
- 是当前时刻的输出,会传递给下一个时间步(作为 ht-1),也可用于产生当前时刻的预测
注意:通常需要在LSTM后接全连接层,将隐藏状态映射到姿态角预测值。
实际训练
1. 训练阶段:学习历史数据的模式
过程:
- 输入:历史序列(如过去 10 个时刻的姿态数据)
- 目标:下一个时刻的真实值
- 学习:通过反向传播调整权重,使预测接近真实值
具体步骤:
- 1、输入历史序列 [X1, X2, ..., X10]
- 2、经过 LSTM 的 6 个步骤,得到隐藏状态 h10
- 3、通过全连接层将 h10 映射为预测值 Y_pred
- 4、与真实值 Y_true 比较,计算损失
- 5、反向传播更新权重(包括三个门的权重)
关键点:
- 模型学习“什么样的历史模式 → 什么样的未来值”
- 例如:连续上升趋势 → 可能继续上升;周期性摆动 → 可能继续摆动
2. 预测阶段:使用学习到的模式
过程:
- 输入:新的历史序列(如最近 10 个时刻的数据)
- 输出:未来时刻的预测值
具体步骤:
- 1、输入历史序列 [X1, X2, ..., X10]
- 2、依次经过每个时间步的 LSTM 计算:
- 时间步 1:处理 X1,得到 h1 和 c1
- 时间步 2:处理 X2,使用 h1 和 c1,得到 h2 和 c2
- ...
- 时间步 10:处理 X10,使用 h9 和 c9,得到 h10 和 c10
- 3、使用最后的隐藏状态 h10 通过全连接层得到预测值
关键点:
- 每个时间步都会更新细胞状态和隐藏状态
- 最后的隐藏状态 h10 包含了整个序列的信息
- 这个信息用于预测未来
Bi-LSTM
单向 LSTM 的局限性
论文中提到,单向 LSTM 在处理时间序列数据时存在局限性:
- 只能利用历史信息:单向 LSTM 只能从序列的开始到结束处理数据
- 无法利用未来信息:对于当前时刻的预测,无法利用未来的数据来优化
- 上下文不全面:在处理复杂动态数据时(如无人船在复杂水域的姿态数据),前后信息密切相关,单向处理会导致信息不全面
Bi-LSTM 的解决方案
Bi-LSTM(Bidirectional LSTM,双向 LSTM)通过同时处理前向和后向序列来解决这个问题:
1. 前向 LSTM 层
- 从序列开始到结束处理数据
- 利用历史信息
- 产生前向隐藏状态
h_t_forward
2. 后向 LSTM 层
- 从序列结束到开始处理数据
- 利用未来信息(在训练时)
- 产生后向隐藏状态
h_t_backward
3. 组合输出(论文公式 3.5)
展开代码Yt = [h_t_forward, h_t_backward]
解释:
- 将前向和后向的隐藏状态拼接
- 最终输出维度 = 2 × 隐藏状态维度
- 同时包含历史信息和未来信息
问题:无人机着船时的控制延迟问题
- 无人机需要根据无人船的姿态实时调整动作
- 但通信延迟导致控制滞后
- 需要提前预测无人船的未来姿态
Bi-LSTM 预测控制器的设计
1. 输入数据
- 无人船过往的姿态数据作为核心输入
- 姿态数据包括:横摇角(Roll)、纵摇角(Pitch)、艏摇角(Yaw)
2. 输出结果
- 未来短时间内的姿态变化预测
- 用于辅助无人机着船控制
- 提前调整动作,克服通信延迟
本文作者:cc
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!