目录
一、数据准备阶段
1、收集无人船姿态数据
无人船姿态数据包括:
- 横摇角(Roll):船体左右倾斜角度
- 纵摇角(Pitch):船体前后倾斜角度
- 艏摇角(Yaw):船体航向角度
- 位置信息:x、y、z坐标(可选)
- 速度信息:线速度、角速度(可选)
- 其他状态:如波浪高度、风速等环境参数(可选)
数据格式:时间序列,每个时间步记录上述所有状态值。
时间步基本概念
时间步是时序数据中的一个采样点,代表某个时刻的状态
假设每0.1秒采集一次无人船的姿态数据:
展开代码时间步0:t=0.0秒,记录 [Roll=5°, Pitch=3°, Yaw=45°] 时间步1:t=0.1秒,记录 [Roll=5.2°, Pitch=3.1°, Yaw=45.5°] 时间步2:t=0.2秒,记录 [Roll=5.5°, Pitch=3.3°, Yaw=46°] 时间步3:t=0.3秒,记录 [Roll=5.8°, Pitch=3.6°, Yaw=46.5°] 时间步4:t=0.4秒,记录 [Roll=6.0°, Pitch=3.8°, Yaw=47°] ...
这里:
- 每个时间步 = 一个采样时刻
- 时间步编号 = 0, 1, 2, 3, 4, ...
- 实际时间 = 0.0秒, 0.1秒, 0.2秒, 0.3秒, 0.4秒, ...
2. 数据组织策略
核心思想:用历史姿态预测未来姿态
确定时间窗口
- 历史窗口长度(seq_length):用过去多少个时间步的数据,例如10、20、30
seq_length = 10 表示: 用过去10个时间步的数据作为输入,如果采样间隔是0.1秒,那么10个时间步 = 1.0秒的历史数据
- 预测步数(pred_length):预测未来几个时间步的姿态
确定样本
样本的定义:
- 样本”是从原始时序数据中切分出的一个训练单元,包含:
- 序列:历史数据(例如10个时间步)
- 标签:要预测的目标(例如未来1个时间步)
- 从原始数据创建样本
假设采集了1000个时间步的无人船姿态数据:
展开代码时间步0: [Roll₀, Pitch₀, Yaw₀] 时间步1: [Roll₁, Pitch₁, Yaw₁] 时间步2: [Roll₂, Pitch₂, Yaw₂] ... 时间步999: [Roll₉₉₉, Pitch₉₉₉, Yaw₉₉₉]
创建样本(假设seq_length=10,pred_length=1):10个时间步的输入 + 1个时间步的目标
单个样本预测过程(假定网络是训练好的):
 样本1:
样本1:
- 输入:时间步0-9的数据(10个时间步的历史),样本中时间步的数据在训练时,按时间顺序,从x₀到x₉依次作为当前输入xt,参与隐藏状态和细胞状态的更新。
- 输出:时间步10的数据(要预测的目标)
展开代码x₀ → h₀, c₀ ↓ x₁ + h₀, c₀ → h₁, c₁ ↓ x₂ + h₁, c₁ → h₂, c₂ ↓ ... ↓ x₉ + h₈, c₈ → h₉, c₉ 最终输出: 使用最后一个时间步的隐藏状态 h₉ h₉包含了整个序列(x₀到x₉)的信息
样本2:
- 输入:时间步1-10的数据
- 输出:时间步11的数据
样本3:
- 输入:时间步2-11的数据
- 输出:时间步12的数据
...
样本990:
- 输入:时间步989-998的数据
- 输出:时间步999的数据
结果:从1000个时间步的数据中,可以创建990个样本
- 批次(Batch)的含义:“批次”是一次训练中使用的样本集合
批次大小=32(一次处理多个样本,利用并行计算):
从990个样本中随机选择32个,这32个样本组成一个批次,用这个批次进行一次参数更新
展开代码样本1, 样本5, 样本10, ..., 样本100(随机选择32个)
下一个批次: 再选择32个样本(可能与之前有重叠), 进行下一次参数更新
展开代码样本3, 样本7, 样本15, ..., 样本200(再随机选择32个)
知道了一个样本是如何得到最后一个隐藏状态的,32个样本共享权值,并行工作时,批次处理的完整过程:
输入:[32, 10, 3]
- 时间步0(32个样本同时处理):
展开代码样本1:x₀¹ → LSTM → h₀¹, c₀¹ 样本2:x₀² → LSTM → h₀², c₀² ... 样本32:x₀³² → LSTM → h₀³², c₀³² 输出:h₀ = [32, 64], c₀ = [32, 64]
- 时间步1(32个样本同时处理):
展开代码样本1:x₁¹ + h₀¹, c₀¹ → LSTM → h₁¹, c₁¹ 样本2:x₁² + h₀², c₀² → LSTM → h₁², c₁² ... 样本32:x₁³² + h₀³², c₀³² → LSTM → h₁³², c₁³² 输出:h₁ = [32, 64], c₁ = [32, 64]
最终输出: 使用h₉ = [32, 64](32个样本,每个样本最后一个时间步的隐藏状态)
二、模型设计阶段
1、模型输入形状
标准输入形状
- 三维张量:[batch_size, seq_length, features]
详细维度说明:
- batch_size:批次大小,例如32、64、128
- seq_length:历史时间步数,例如10、20、30
- features:每个时间步的特征数
例子:只预测3个姿态角
- 批次大小 = 32
- 序列长度 = 10
- 特征数 = 3(Roll、Pitch、Yaw)
输入形状:[32, 10, 3]
- 含义:32个样本,每个样本包含10个历史时间步,每个时间步有3个姿态角值
2、LSTM层:学习时序模式
输入形状:[32, 10, 3]
逐个时间步处理过程:
时间步0的处理
输入到LSTM单元:
- 当前输入 xt:样本中时间步0的数据,形状 [3](例如:[Roll₀, Pitch₀, Yaw₀])
- 前一时刻隐藏状态 ht-1:初始化为全零,形状 [hidden_size](例如:[0, 0, ..., 0])
- 前一时刻细胞状态 ct-1:初始化为全零,形状 [hidden_size]
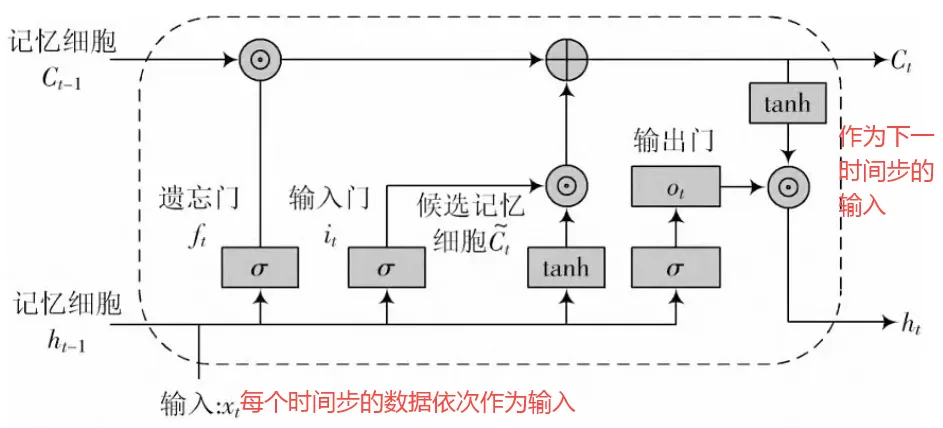
LSTM内部计算:
- 步骤1:拼接输入
展开代码concat_input = [ht-1, xt] = [64维隐藏状态, 3维输入] = 67维向量
- 步骤2
- 计算遗忘门、输入门和候选细胞状态,更新细胞状态,计算输出门和隐藏状态结果:64维向量(新的隐藏状态,短期记忆)
时间步0的输出:
- 隐藏状态 h₀:[64](包含时间步0的信息)
- 细胞状态 c₀:[64](长期记忆载体)
时间步1的处理
输入到LSTM单元:
- 当前输入 xt:样本中时间步1的数据,
- 前一时刻隐藏状态 ht-1:时间步0的隐藏状态 h₀,形状 [64]
- 前一时刻细胞状态 ct-1:时间步0的细胞状态 c₀,形状 [64]
LSTM内部计算:
- 步骤1:拼接输入
展开代码concat_input = [ht-1, xt] = [64维隐藏状态, 3维输入] = 67维向量
- 步骤2:LSTM内部计算
时间步0的输出:
- 隐藏状态 h₀:[64](包含时间步0的信息)
- 细胞状态 c₀:[64](长期记忆载体)
LSTM层的输出
若只输出最后一个时间步(每个样本只取最后一个时间步(时间步9)的隐藏状态): 输出形状:[32, 64]
- 32:32个样本
- 64:最后一个时间步的隐藏状态维度
展开代码样本1:时间步0-9 → h₉ → [64维向量] 样本2:时间步0-9 → h₉ → [64维向量] ... 样本32:时间步0-9 → h₉ → [64维向量] 最终:32个样本,每个样本一个64维向量 形状:[32, 64]
3、全连接层:映射到姿态角预测
全连接层目的:将抽象的隐藏状态映射到具体的姿态角预测值
输入:LSTM的隐藏状态
- 输入形状:[32, 64]
过程:
- 变换:output = W · hidden_state + b
- 激活函数
输出:
- [Roll_pred, Pitch_pred, Yaw_pred] (3维预测值)
4、模型输出形状
输出形状取决于预测任务,例:预测未来1个时间步的姿态
- 输出形状:[batch_size, features] 或 [batch_size, 1, features]
例子:
- 输入:[32, 10, 3]
- 输出:[32, 3](32个样本,每个样本预测3个姿态角)
展开代码样本1的预测: 未来时间步10: [Roll₁₀, Pitch₁₀, Yaw₁₀] 样本2的预测: 未来时间步11: [Roll₁₁, Pitch₁₁, Yaw₁₁]
三、如果模型没训练好,那么训练阶段是如何完成的
1、前向传播:历史姿态 → LSTM → 预测姿态
训练阶段:使用真实数据作为标签
数据准备:假设采集了1000个时间步的无人船姿态数据
1、创建训练样本
样本1:
- 输入(X):时间步0-9的数据(10个时间步的历史)
- 输出(y,标签):时间步10的数据(这是采集到的真实数据),不是模型预测的
展开代码y = [6.2, 4.0, 47.5] ← 真实采集的数据
样本2:
- 输入(X):时间步1-10的数据
- 输出(y,标签):时间步11的数据(真实采集的数据)
...
2、前向传播
展开代码输入:样本1的时间步0-9数据 ↓ LSTM处理 ↓ 全连接层 ↓ 模型预测:y_pred = [6.1, 3.9, 47.3] ← 这是模型预测的值
2、计算损失:预测值与真实值比较(MSE)
展开代码真实标签:y_true = [6.2, 4.0, 47.5] ← 这是采集到的真实数据 模型预测:y_pred = [6.1, 3.9, 47.3] ← 这是模型预测的值 损失 = MSE(y_pred, y_true) = (6.1-6.2)² + (3.9-4.0)² + (47.3-47.5)² = 0.01 + 0.01 + 0.04 = 0.06
3、反向传播:更新权重
4、迭代优化:多个epoch直到收敛
本文作者:cc
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!